

Reviewed by:
Rokas Stankevicius

Founder @ aiclicks.io
Last updated:
Expert Verified


Free AI visibility audit
Key Takeaways
Getting cited by AI is two problems pretending to be one: being retrievable (the model can find and parse your content) and being trusted (the model has enough corroboration to actually use you). Most advice only solves the first.
On-page work (schema, structure, freshness) is the cover charge, not the win. It gets you into the consideration set and stops there.
Citations are won on consensus: your brand showing up, described consistently, across the third-party sources AI cross-references. Reddit, G2, YouTube, listicles, industry media.
Original data is the most citable thing you can publish. AI models reach for facts they can attribute, and a proprietary stat has no competing source.
You can't fix what you can't see. AIclicks shows you the exact prompts buyers ask, the sources AI pulls to answer them, and whether your brand made the cut.
"How to get cited by AI" has become the most-written, least-useful genre of content marketing on the internet.
Search it and you'll get forty articles that say the same five things: add schema, lead with the answer, phrase your headings as questions, drop in an llms.txt file, refresh your content quarterly.
The advice isn't wrong, it's just incomplete in a way that quietly wastes a lot of teams' time. Every one of those articles explains how to make your content eligible for a citation but none of them explains how citations are actually won.
Here's what the guides miss. In AI search, the best website doesn't win. The brand that wins is the one you keep running into everywhere, on Reddit, on G2, in three different listicles, in a YouTube review; all saying roughly the same thing about it.
AI models don't cite the best page. They cite the brand enough independent sources agree on. Which means most of the citation-winning work happens somewhere the typical checklist never looks: off your website entirely.
We spend our days looking inside citation data, which prompts buyers actually ask, which sources AI pulls, which brands make the answer and which don't. This blog covers all of it, the on-page basics that make you eligible, and the off-page work that gets you chosen.
Getting Cited Is Two Problems, Not One
Most teams treat "get cited by AI" as a single goal. It's two, and they're won in completely different ways.
First, retrieval. The model has to find your page, crawl it, parse it, and decide it's relevant to the query. This is a technical and structural problem. If AI crawlers can't access your site, or your content is buried in JavaScript, or your page doesn't clearly answer the question, you never make it to the consideration set.
Second, trust. Once your page is in the consideration set alongside dozens of others, the model has to decide it's credible enough to actually cite. This is where most citations are won and lost. AI models don't cite a claim because one page made it. They cite it when multiple independent sources agree. That agreement is the consensus signal, and it's mostly built off your own website.
Tactics 1 to 3 fix retrieval. Tactics 4 to 8 build trust. Both matter. But if you're short on time, spend it on trust. Almost every brand in your category has already done the retrieval homework. Almost none of them have done the trust work properly. That gap is your opportunity.
Part 1: Become Retrievable
Tactic 1: Check whether AI crawlers can even get in
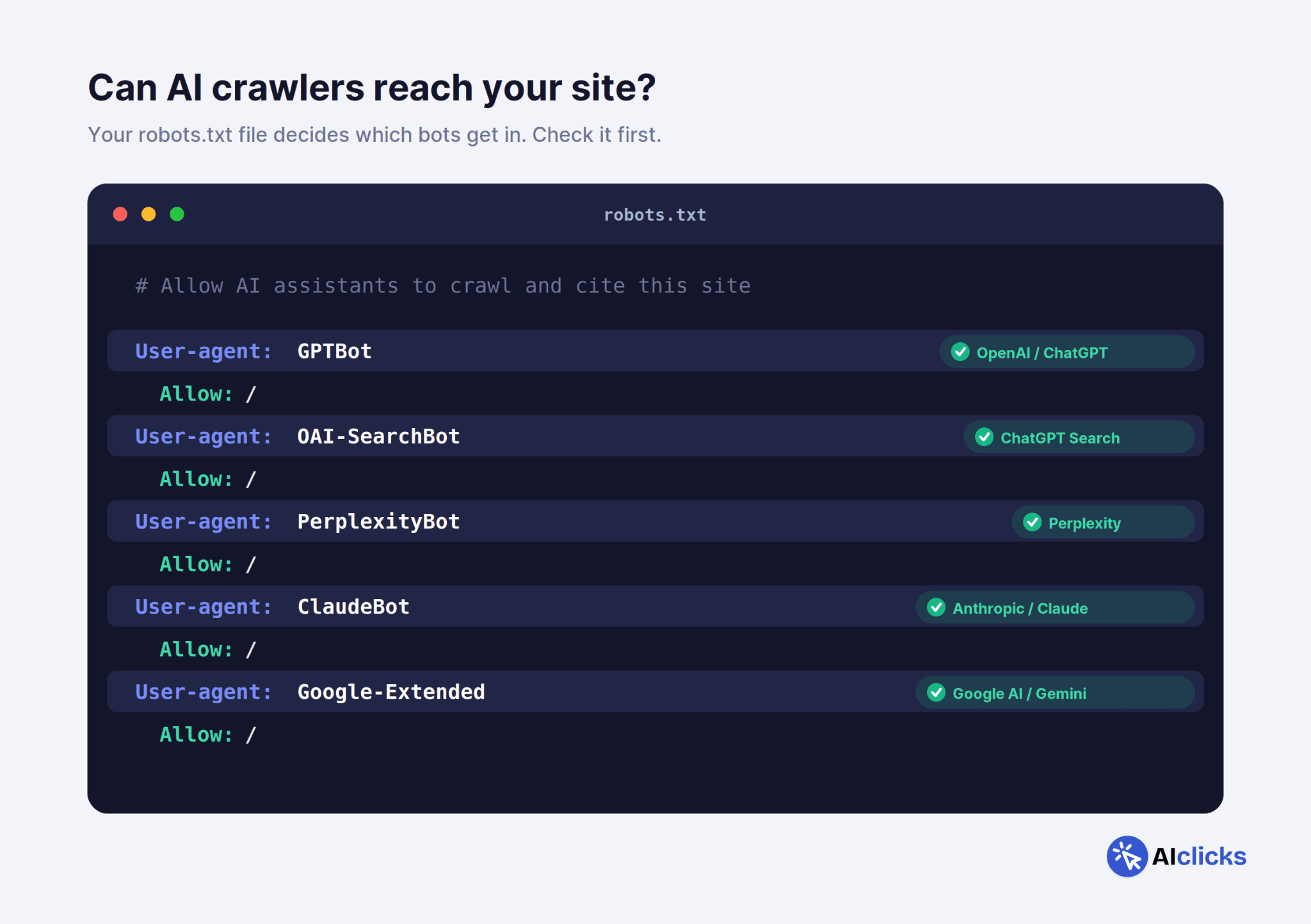
The least glamorous item on this list is also the most common reason brands get zero AI citations. The crawlers never got in.
Your robots.txt file decides which bots are allowed to crawl your site. Plenty of sites are still running robots.txt written years ago, back when "AI crawler" wasn't a phrase anyone used.
If GPTBot, PerplexityBot, ClaudeBot, or Google-Extended hit a wall there, you are invisible to the platforms those bots feed. Your content quality is irrelevant. The model never sees it.
What to do:
Go pull up yourdomain.com/robots.txt right now and check it against the current AI crawler user agents: GPTBot and OAI-SearchBot (OpenAI), PerplexityBot (Perplexity), ClaudeBot (Anthropic), Google-Extended (Google's AI training), and Bingbot (powers Copilot).
Decide deliberately which to allow. For most brands chasing citations, the honest answer is "all of them."
While you're in there, confirm your important pages aren't quietly blocked by a noindex tag, a login wall, or an overzealous firewall rule from your CDN.
This one takes just a few hours and is the cheapest, highest-certainty fix you'll find on this list, and a genuinely surprising number of brands have never checked.
Tactic 2: Structure your content the way a model actually reads it
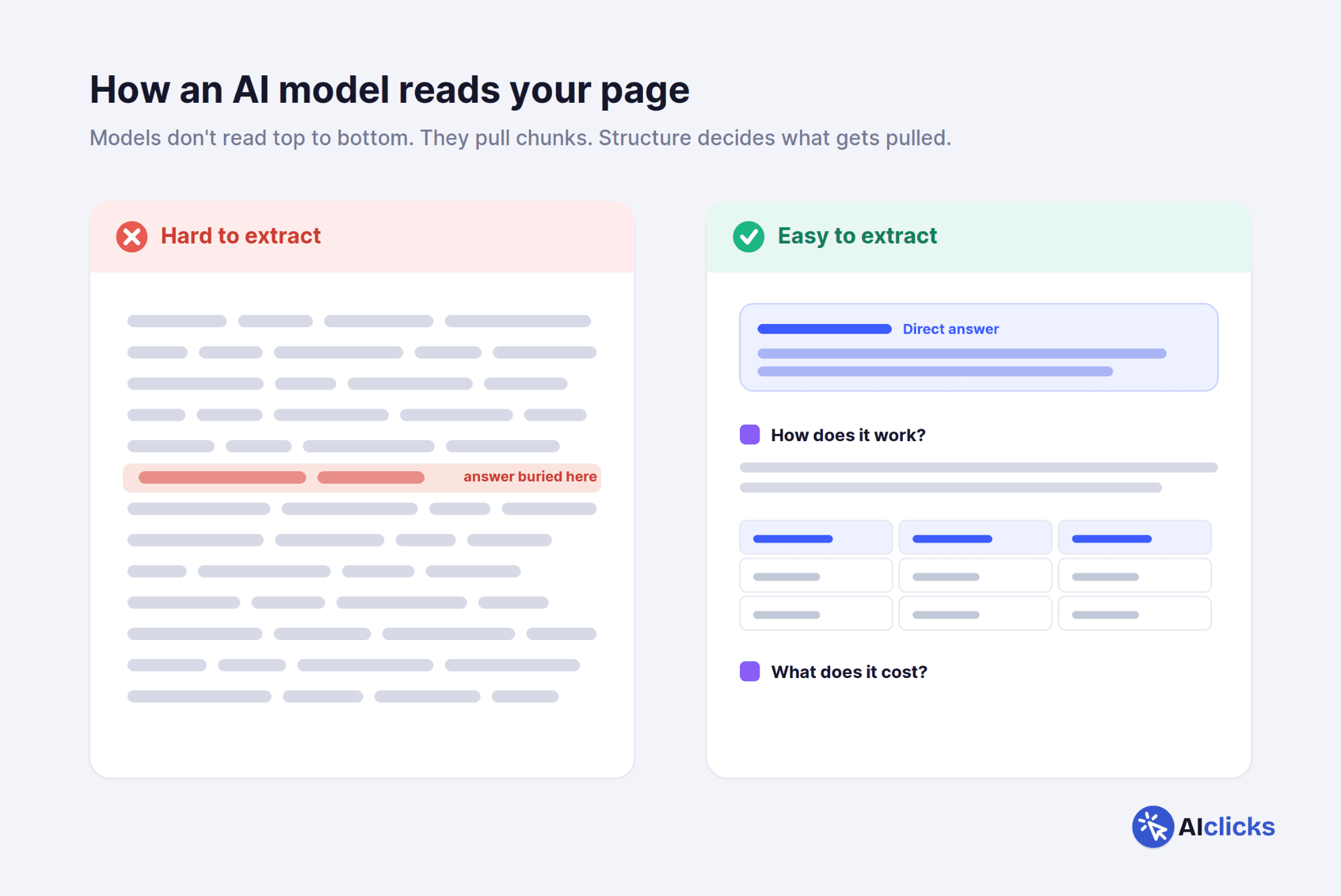
AI models don't read your page the way a human does. They chunk it. A retrieval system breaks your content into segments, embeds them, and pulls the segments that best match the query.
Content that's structured into clean, self-contained chunks gets extracted cleanly. Content that buries the answer in paragraph six of a meandering intro does not.
What to do:
Lead with the answer. For any page targeting a question, state the direct answer in the first two or three sentences, then expand. Don't make the model dig.
Use H2s and H3s phrased the way people actually ask questions. "How much does X cost" beats "Pricing."
Write self-contained sections. Each section should make sense if it were the only part of the page a model retrieved.
Use lists and tables for anything comparative or sequential. AI models extract structured data more reliably than prose for these formats.
Add a short, factual summary near the top of long pages. It gives the model a clean chunk to pull.
None of this is exciting. It also won't win you a single citation on its own. But badly structured content reliably loses citations, so it's worth getting right and then never thinking about again.
Tactic 3: Send the freshness and schema signals
Two signals tell AI models your content is current and trustworthy enough to retrieve: freshness and structured data.
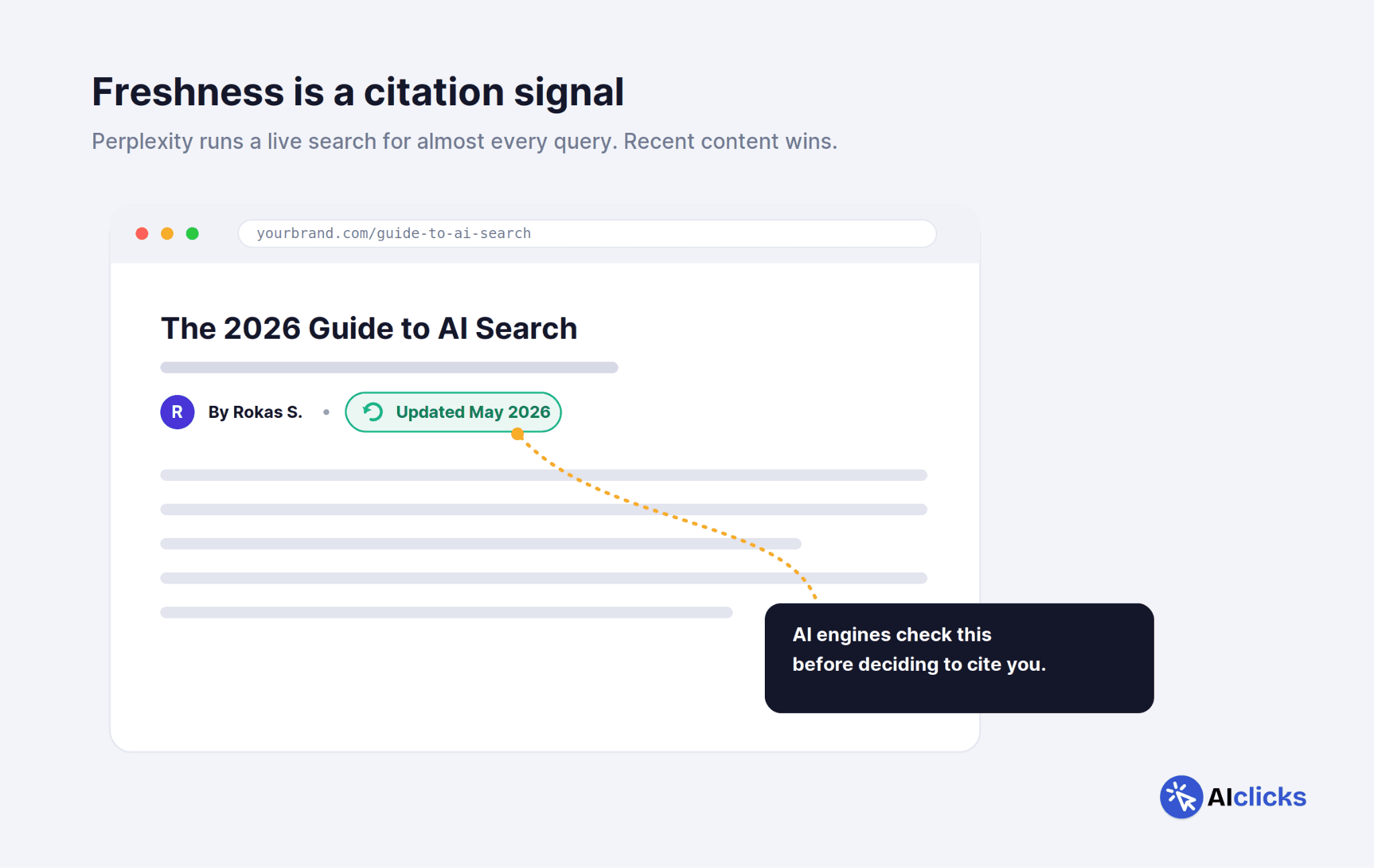
Freshness matters more than most teams think, and more on some platforms than others. Perplexity, which runs live web searches for nearly every query, weights recency heavily. A page last updated in 2023 competes badly against one updated last month.
Schema markup gives AI models machine-readable context about what your page is. It won't manufacture a citation, but it removes ambiguity about what your content covers and who published it.
What to do:
Show real, visible "last updated" dates on key pages, and make the updates real. Refresh statistics, examples, screenshots, and product references on a quarterly cycle.
Add relevant schema: Article, FAQPage, HowTo, Organization, and Product where applicable.
Keep your Organization schema and your "about" information consistent across every page. This feeds the entity work in Tactic 7.

That's the foundation done. If Tactics 1 through 3 are handled, you're retrievable. Now comes the part that actually decides whether you get cited.
Part 2: Become trusted
Tactic 4: Find the exact prompts and sources AI uses in your category
This is where most Generative Engine Optimization (GEO) programs go wrong before anyone writes a word.
Teams pull keywords out of their old SEO tool, optimize for those, and hope it carries over to AI search. It mostly doesn't. The questions people ask ChatGPT look nothing like the queries they type into Google, and the sources AI leans on to answer them are not the ten blue links you're used to competing for.
So the real work starts with two questions. What are buyers actually asking AI tools in your category? And which pages do those tools cite when they answer?
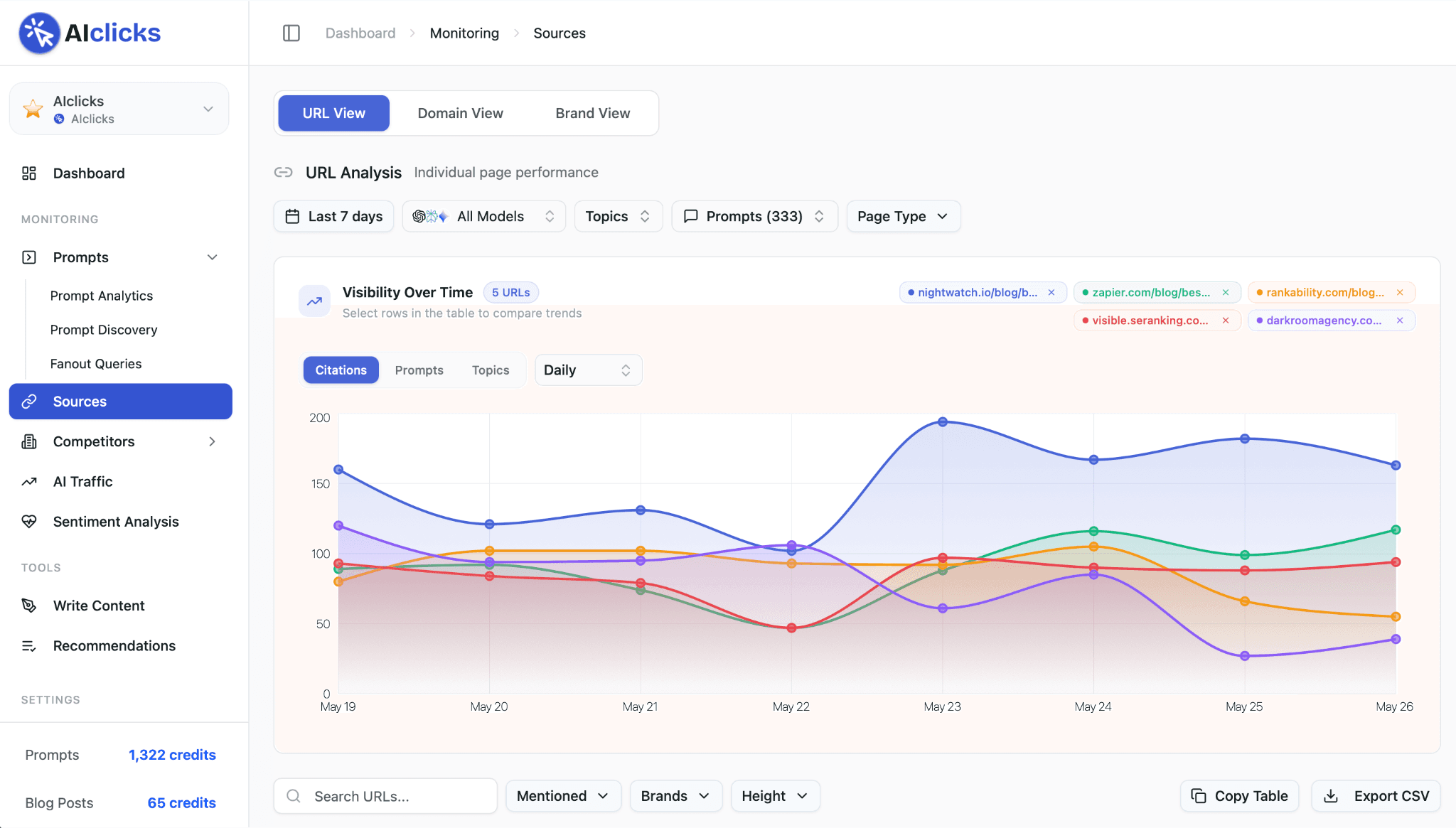
This is the core job AIclicks is built for. Inside the platform, you track the real prompts buyers ask across ChatGPT, Perplexity, Gemini, Google AI Overviews, and AI Mode. The Sources view then shows you every URL those models retrieve from to answer those prompts, ranked by how often each one is cited.
What to do:
Build a list of the prompts your buyers actually ask. Use AIclicks' prompt tracking and Prompt Discovery to find them rather than guessing from keyword data.
Open the Sources view and sort by citation frequency. The pages at the top are the ones shaping AI answers in your category right now.
Filter for whether your brand is mentioned on each source. The high-frequency pages where you're absent are your priority target list.
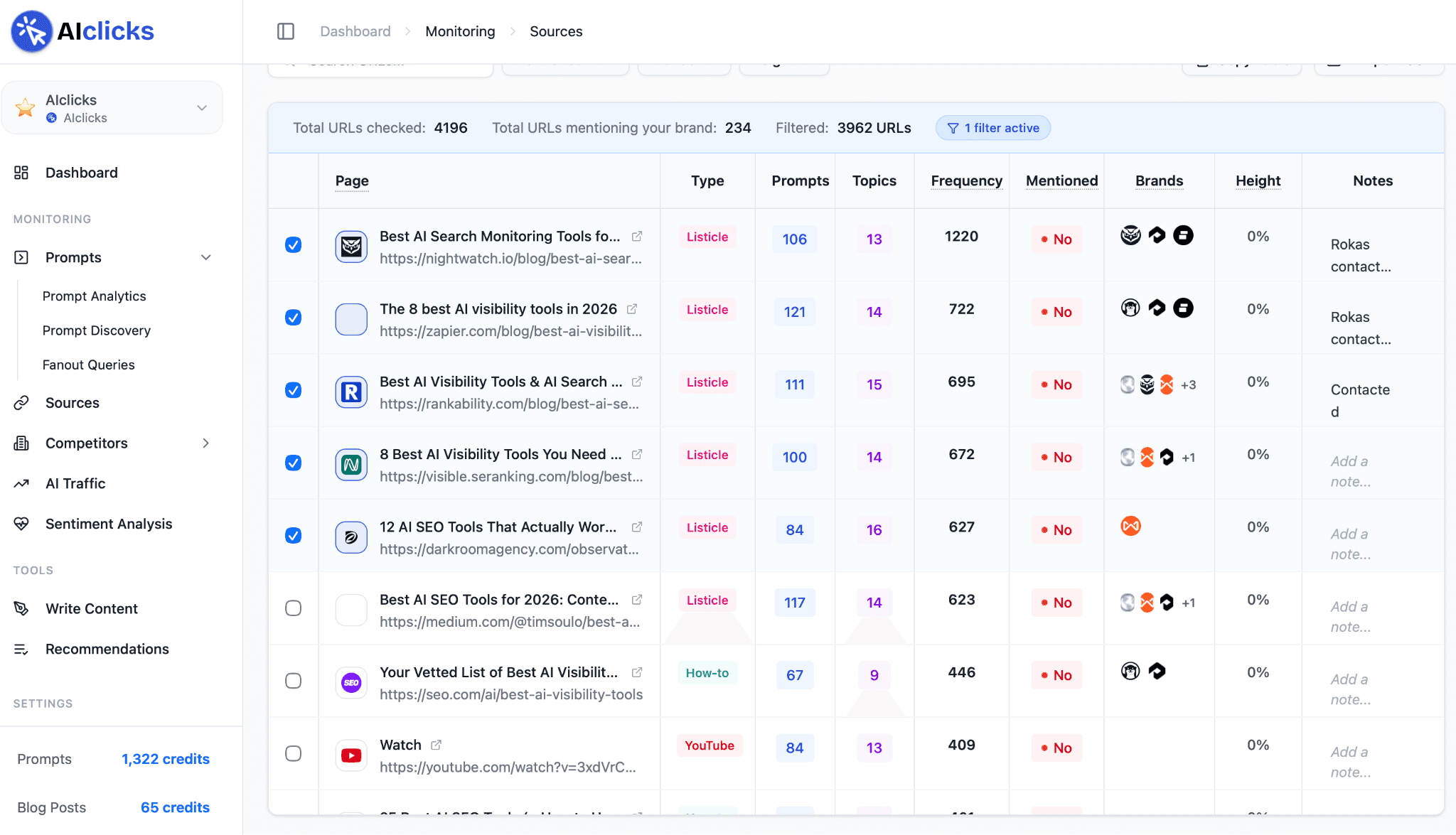
Learn more about what prompts to track.
This tactic doesn't produce content. It produces a map. Every tactic after this one depends on having it.
Tactic 5: Build the consensus signal across third-party sources
This is the tactic that wins citations, and the one almost no checklist covers properly.
AI models don't trust a claim because your website made it. They trust it when independent sources corroborate it. If your product shows up consistently across Reddit threads, G2 reviews, YouTube walkthroughs, industry listicles, and LinkedIn commentary, all describing you in roughly the same way, the model gains confidence that you're a real, credible answer. That repeated agreement across sources is the consensus signal.
The implication is uncomfortable for content teams: a meaningful share of the work that gets you cited happens on pages you don't own and can't directly publish to.
Teams keep asking us how to make their own content more citable. It's the wrong question. In our data, the brands that win AI citations are the ones AI sees described consistently across Reddit, G2, YouTube, and industry media. The model is looking for agreement between independent sources. You can't manufacture that on your own domain. You earn it everywhere else, and your website just confirms it.
- Rokas Stankevicius, Founder, AIclicks
What to do:
Take the priority source list from Tactic 4 and work it methodically. For each high-frequency page where you're absent, identify the realistic path to a mention: a review platform profile, a pitch to a listicle's author, or genuine community participation.
Claim and optimize your profiles on review platforms like G2, Capterra, and Trustpilot, then run a structured review-collection campaign with current customers. AI models cite these heavily for "best [category]" prompts.
Earn your way into the listicles AI already cites. Pitch the writer with a specific angle: original data, a differentiated feature, or a customer outcome the current list misses.
Participate authentically in the communities where your category is discussed. Reddit is the highest-value and the trickiest. Direct promotion backfires; real participation by named experts over months is what works.
Keep your messaging consistent everywhere. The consensus signal depends on sources describing you the same way. Mixed positioning weakens it.
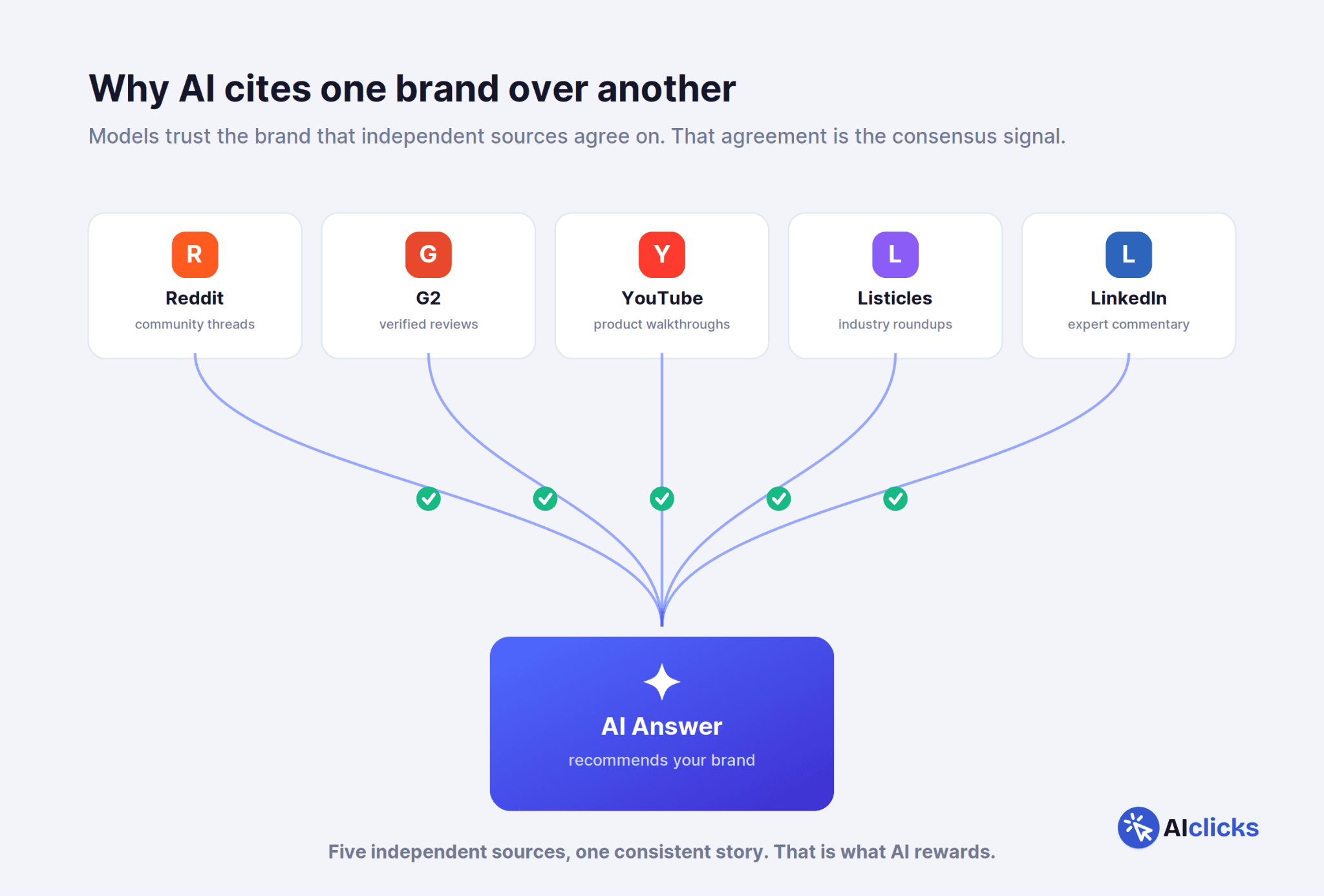
One rule ties all of it together: keep your messaging consistent. The consensus signal depends on sources telling the same story about you. If your positioning is different in every place, you're handing the model noise instead of a signal.
Tactic 6: Publish original data nobody else has
If you do one thing on the content side, do this. Original data is the single most citable content format in existence.
AI models are built to retrieve verifiable, attributable facts. When a model needs a statistic, a benchmark, or a number to support an answer, it reaches for a source it can cite. If that number is yours, pulled from your survey, your product data, or your original analysis, you become the citation. And unlike opinion content, which competes with everyone, a proprietary data point has no competition. You're the only source for it.
What to do:
Run one original research piece per quarter. A survey of your customers or industry, a benchmark report, an analysis of data only you have access to.
Lead with the numbers. Put the most citable stat in a headline, a chart, and a one-sentence summary so models can extract it cleanly.
Make the data quotable. Round figures, clear phrasing, explicit attribution to your brand and the study.
Distribute it into the sources from Tactic 4. Original data is the easiest thing to get other people to cite, which feeds your consensus signal in Tactic 5.
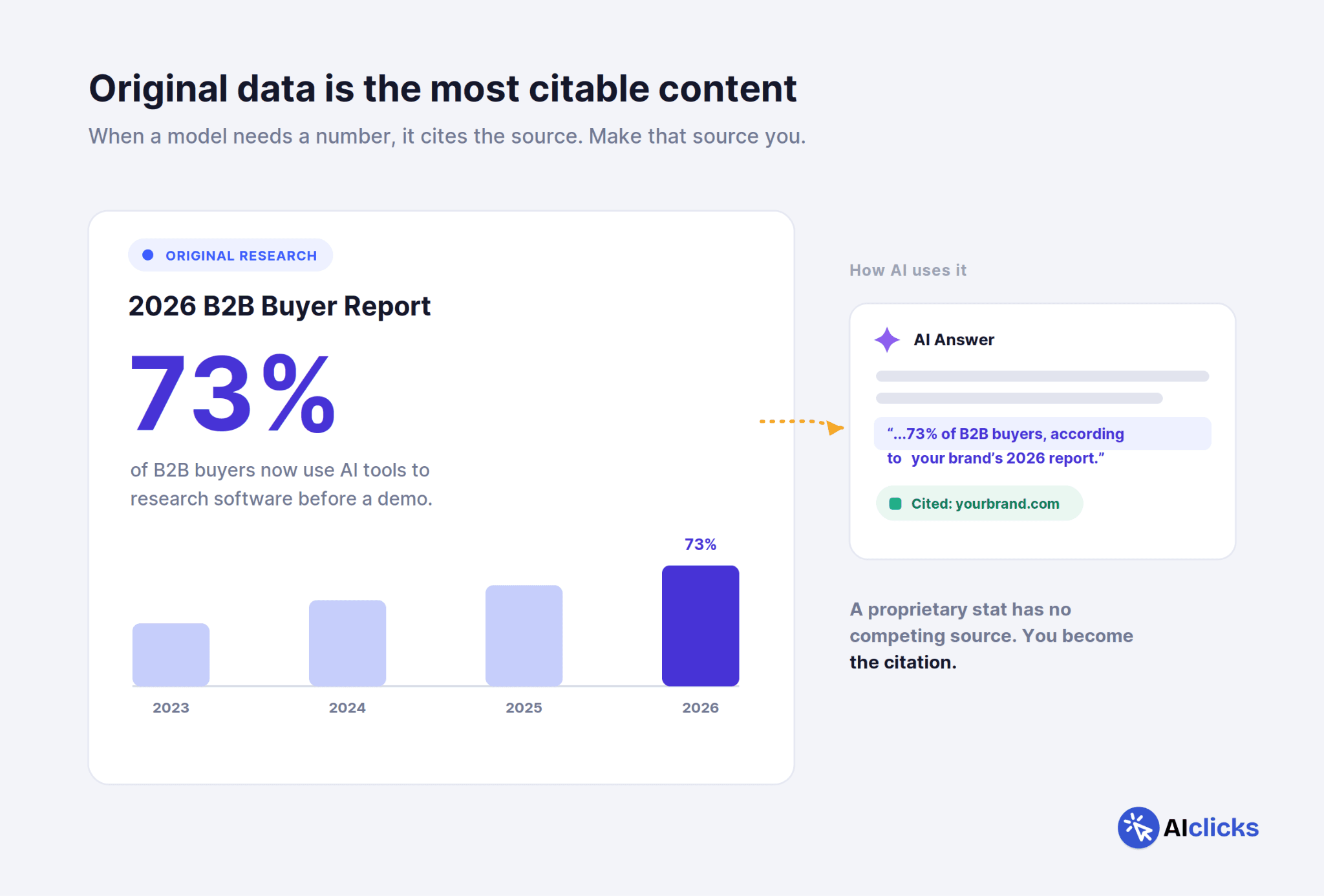
A strong data study earns citations for years. It's the highest-return content investment a GEO program can make.
Tactic 7: Fix your entity so AI understands what you are
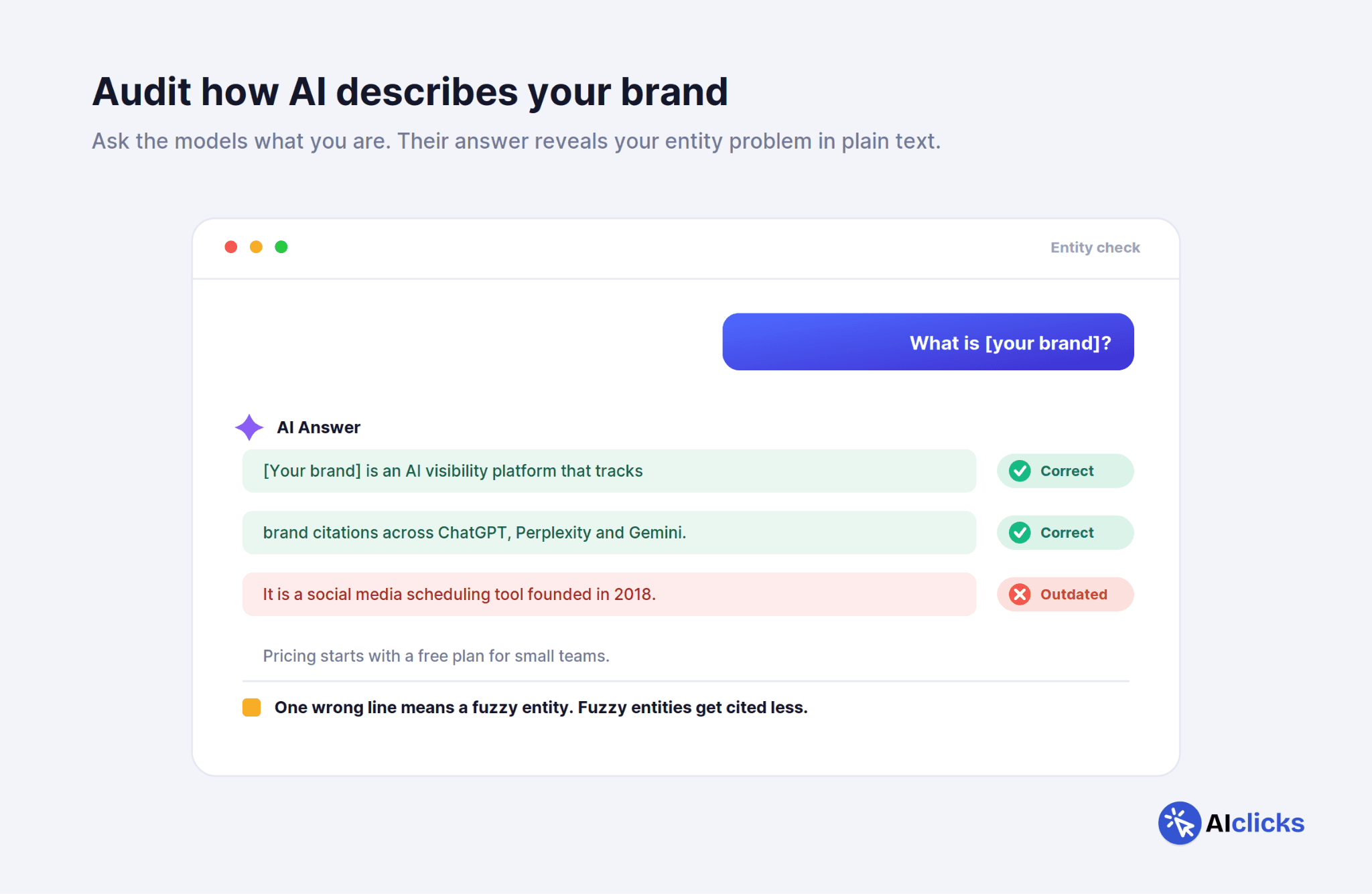
AI models don't think in pages. They think in entities (people, companies, products, concepts) and the relationships between them. Before a model can cite you confidently, it needs a clear, consistent understanding of what your brand is, what category you're in, and who you compete with.
If different sources describe your company differently, with a different category, different positioning, or outdated product descriptions, the model's understanding of your entity is fuzzy, and fuzzy entities get cited less.
What to do:
Write one canonical description of your company, category, and core offering. Use it consistently on your site, social profiles, review platforms, and press materials.
Get the foundational entity sources right: a clean, factual Wikipedia presence if you qualify, an accurate Wikidata entry, a complete Google Business Profile, consistent LinkedIn and Crunchbase data.
Use Organization and Product schema to state your entity facts explicitly.
Audit how AI currently describes you. Ask ChatGPT, Perplexity, and Gemini "what is [your brand]" and "what category is [your brand] in." If the answers are wrong or vague, that's your entity problem showing up directly.
Tactic 8: Monitor your citations and defend against bad ones
Getting cited is not a one-time project. AI answers change constantly as models update, retrieval pipelines shift, and new content gets published. A brand cited heavily this month can fade next month without anything obvious changing on its own site.
There's also a defensive side most teams ignore. AI models sometimes cite sources that describe your brand inaccurately or negatively. An outdated review, a wrong pricing figure in a Reddit thread, a competitor comparison that misrepresents your features. Any of these can propagate into AI answers and you won't know unless you're watching.
What to do:
Track your citation frequency, visibility, and share of voice across AI platforms on an ongoing basis. AIclicks monitors all of this at the prompt and source level.
Watch sentiment on the sources AI cites about you. Being mentioned isn't always good. AIclicks' sentiment analysis flags when negative or inaccurate pages are driving your visibility.
When you find an inaccurate cited source, act on it: request a correction, add accurate context in the thread, or publish the correct information somewhere AI will retrieve it.
Review your citation data monthly and feed what you learn back into Tactics 4 through 7.
Learn more about AI optimization here.
How AIclicks Helps You Get Cited
Three of the eight tactics above depend on data that traditional SEO tools simply don't have. AIclicks is built to help with it.
Prompt tracking and discovery show you the real questions buyers ask AI tools in your category, so you optimize for actual demand instead of guessing from keywords.
The Sources view reveals every URL AI engines retrieve from to answer those prompts, ranked by frequency, filterable by whether your brand is mentioned. This is your consensus-signal target list.
The Get Mentioned workflow turns the high-frequency sources where you're absent into a prioritized, trackable outreach queue.
Citation, visibility, and share-of-voice metrics measure whether your work is moving the needle, broken down by prompt and competitor.
Sentiment analysis flags when inaccurate or negative sources are shaping how AI describes you.
If you want to see which prompts, sources, and citations are shaping your brand's AI visibility right now, try AIclicks here. Most teams find their biggest citation gap in the first hour with the data.
Frequently Asked Questions (FAQs)
1. How do I get my content cited by ChatGPT?
Two things have to happen. Your content has to be retrievable, meaning crawlers like GPTBot and OAI-SearchBot can reach and parse it. And your brand has to be trusted, meaning multiple independent sources corroborate what you say. Fix crawler access first, structure your content for clean extraction, then build a consistent presence across the third-party sources ChatGPT cross-references: Reddit, review platforms, industry media, and listicles.
2. Does schema markup actually help you get cited by AI?
It helps, but it won't carry you. Schema gives a model machine-readable context about what your page covers and who published it, which smooths out retrieval. It does not manufacture a citation. Treat schema as part of the foundation, not as a strategy on its own.
3. Why isn't my brand cited by AI even though it ranks well on Google?
Because ranking on Google doesn't reliably transfer. Research found only 11% of domains are cited by both ChatGPT and Perplexity. The usual culprits are blocked crawlers, a missing consensus signal (your brand isn't mentioned across the third-party sources AI trusts), or a blurry entity (the model isn't confident what you are).
4. What kind of content is most likely to get cited by AI?
Original data, by a wide margin. AI models reach for verifiable, attributable facts, and proprietary statistics, benchmarks, and research give them something to cite with no competing source. Direct-answer content (clean definitions, comparisons, how-to steps) performs well too, because it's easy to extract.
5. How long does it take to get cited by AI?
Retrieval fixes like crawler access and content structure can show results within weeks, once pages get re-crawled. The trust work takes longer, usually 3 to 6 months for the first real movement and 9 to 12 for compounding results, because it depends on PR, community engagement, and review-platform momentum that don't happen overnight.
6. Can I pay to get cited by AI?
No. As of 2026 there's no paid placement in AI citations. A few platforms are testing ad units alongside answers, but the cited sources themselves are earned through retrievability, content quality, and consensus across trusted sources. The work in this playbook is the path.
7. How do I track whether AI is citing my brand?
Use a dedicated AI visibility platform. AIclicks tracks citations, visibility, and share of voice across ChatGPT, Perplexity, Gemini, Google AI Overviews, and AI Mode at the prompt and source level, and flags the sentiment of the pages AI cites about you. Standard analytics and SEO tools can't see this layer.
Our Content:

Introducing Engage Online: Join the Conversations Your Buyers Are Already Having

Why AI Keeps Citing Third-Party Sources Instead of Your Website

Best AI Overviews Trackers in 2026

8 Best Scrunch AI Alternatives in 2026 (Tested and Compared)

Introducing AIclicks Writer 2.0: Write What AI Engines Actually Cite

How to Find and Choose Prompts to Track for AI Visibility
Any questions left?
Book a call here: